Products
Product Lineup
Turnkey, one-box operation, one-click start. Scale linearly from one unit to ten thousand. Your data stays local.


微算-B Basic
Small-scale AI inference, data analysis, training. Turnkey, 48-72h deployment. Free during pilot.
~¥98K (free during pilot)
Leasing: ¥2,000/mo
View Details →
微算-P Professional
Mid-scale AI training & inference, industrial edge. Multi-node cluster with EBOF all-flash, on-demand scaling.
¥2-5M
View Details →
微算-E Enterprise
Large-scale model training, HPC. Thousand-card heterogeneous cluster, PB-scale storage. Custom solutions.
¥5M+ (custom)
View Details →Product Architecture
Weisuàn integrates compute, storage, and management, built on compute-storage disaggregation and EBOF.
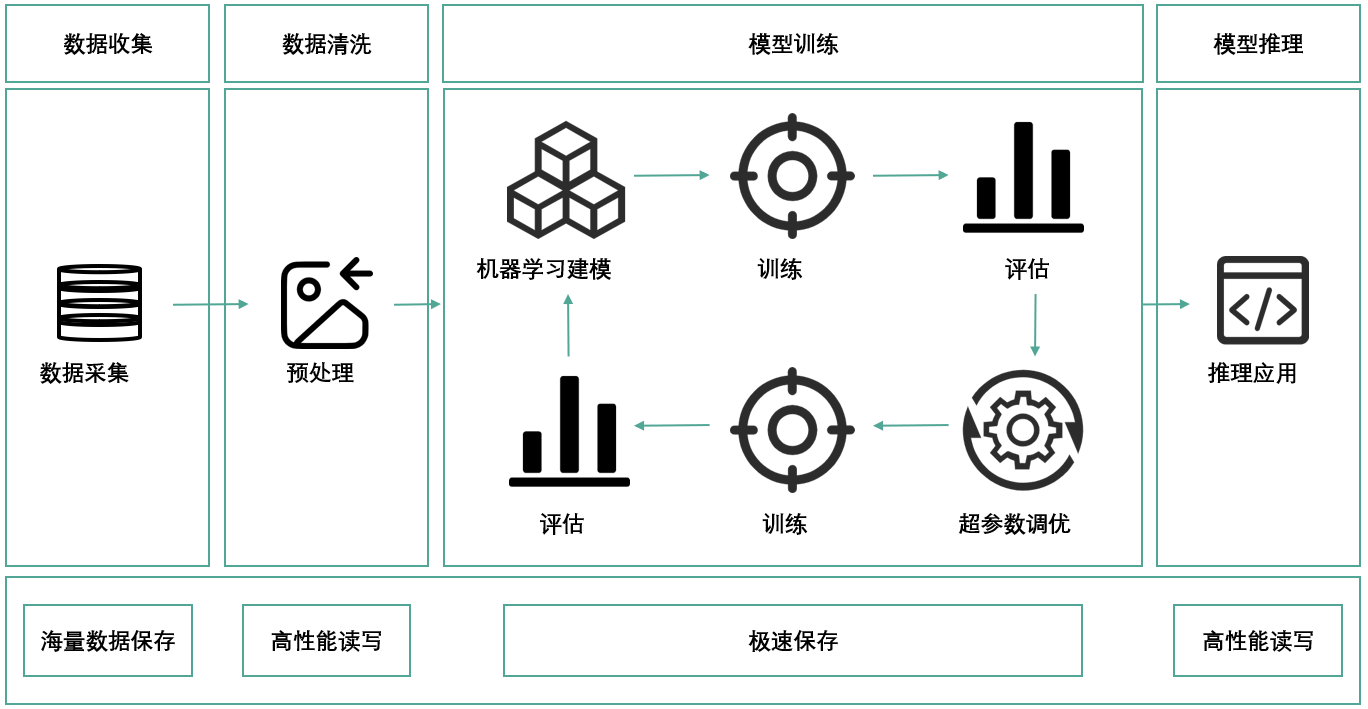

Scaling Path
Scale from one unit to ten thousand. Like building a wall brick by brick, or coupling train cars.
| Stage | Scale | Compute | Investment |
|---|---|---|---|
| Single Unit | 1 units | 1 PFLOPS | ¥98K (free) |
| Small Cluster | 5-10 units | 40-80 PFLOPS | ¥4-8M |
| Medium Cluster | 50-100 units | 400-800 PFLOPS | ¥40-80M |
| Large Cluster | 500-1000 units | 4-8 EFLOPS | ¥4-8亿 |
| Mega Scale | 5000-10000 units | 40-80 EFLOPS | ¥40-80亿 |
Leasing from ¥2,000/month
No upfront investment needed for local AI compute. Data stays local, deploy in 48-72 hours. 3-year TCO significantly lower than traditional or cloud solutions.